利用cheerio模块简单爬取NBA球队排名
已被阅读 2795 次 | 文章分类:nodejs | 2018-12-05 00:09
nodejs中有一个html和xml的解析模块cheerio,用法和浏览器端的jquery库极为一样;无非就是对html的所有dom对象通过css selector进行查找;所以只要你会点jquery的知识;那么浏览器爬虫对你来说就极为简单了
一:先看官方的一个简单例子
运行该demo之前,首先配置好你的nodejs环境,可在其他章节查看详细教程
//安装模块
npm install --save cheerio
let cheerio = require('cheerio') // 引入模块
let $ = cheerio.load('<h2 class="title">Hello world</h2>') // 获取html document
$('h2.title').text() // 获取内容
$('h2').addClass('welcome') // 添加类名
console.log($('h2.title').text()); // Hello world
console.log($.html()); // <html><head></head><body><h2 class="title welcome">Hello world</h2></body></html>
可以看到基本思路是获取cheerio模块,加载html文件,这里的html文件是写好的;然后通过css selector获取指定内容;
二:通过url获取html
1.首先使用nodejs自带的http模块,通过get方法请求地址,然后通过回调函数res的data事件获取html对象;这里以百度首页为例
var http = require("http");
http.get("http://www.baidu.com", (res) =>{
var html = '';
res.on('data', (chunk) =>{
html += chunk;
console.log(html);
})
});
2. 爬去百度首页右上角的菜单内容

F12 查看html结构;结构是非常简单的
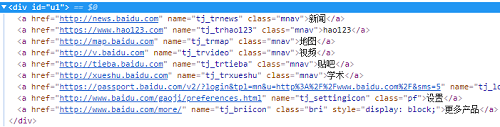
通过$('#ul a')获取所有a标签,然后遍历取值便可得到想要的数据
let http = require("http");
let cheerio=require('cheerio');
http.get("http://www.baidu.com",(res)=> {
let html = '';
res.on('data', function(chunk) {
html += chunk;
})
res.on('end', ()=> {
//数据获取完,执行回调函数
callback(html);
});
});
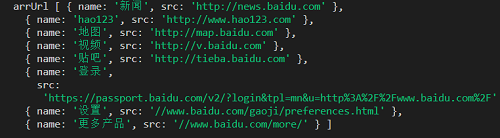
function callback(html){
let $ = cheerio.load(html),arrUrl=[];
$('#u1>a').each((index, element)=> {
let src=$(element).attr('href');
let name=$(element).text();
arrUrl.push(
{
name:name,
src:src
});
});
console.log("arrUrl",arrUrl);
三:定时爬取二:
1. 安装moment和node-schedule 三方包,方便使用;moment用来格式化时间,省去自己格式化的麻烦;node-schedule:参考地址;定时执行的一个库,定时的时间格式有三种,可根据情况使用;
//安装模块
npm install --save moment
npm install --save node-schedule
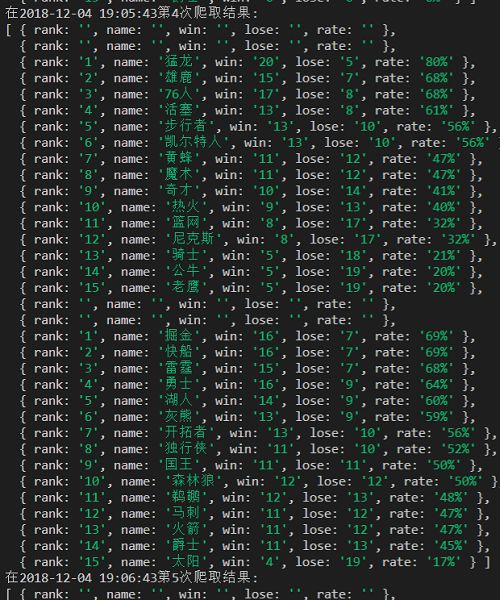
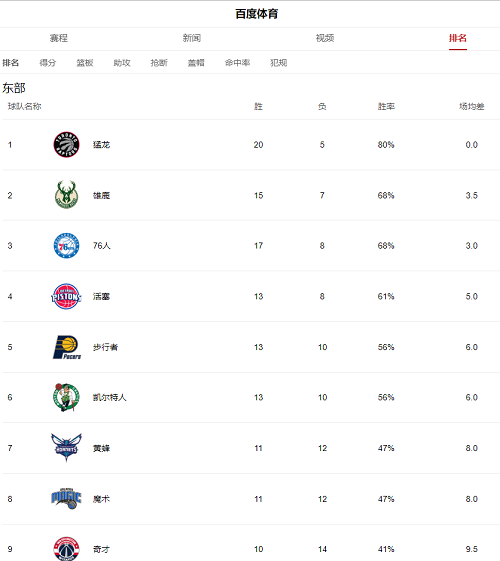
2. 爬虫nba球队排名信息
/**
* '42 * * * * *' 每分42秒执行
* '42 30 * * * *' 每小时30分42秒执行
* '42 30 16 * * *' 每天16:00 30分42秒执行
*
*/
let j = schedule.scheduleJob('42 * * * * *', function(){
let http = require('http'),cheerio = require('cheerio'), pageUrl = 'http://tiyu.baidu.com/match/NBA/tab/%E6%8E%92%E5%90%8D';
http.get(pageUrl, (res)=>{
let html = '';
res.on('data', (data)=>{
html += data;
});
res.on('end', ()=>{
callback(html);
});
});
function callback(html) {
let $ = cheerio.load(html),arrUrl = [];
$('.wa-tiyu-rank-basketball > div').each((index, element)=> {
let rank=$(element).find('.wa-tiyu-rank-basketball-row >a > div.c-span1').first().text().trim();
let name=$(element).find('.wa-tiyu-rank-basketball-row >a > div.c-span3').text();
let win=$(element).find('.wa-tiyu-rank-basketball-row >a > div.wa-tiyu-rank-basketball-win').text().trim();
let lose=$(element).find('.wa-tiyu-rank-basketball-row >a > div.wa-tiyu-rank-basketball-lose').text().trim();
let rate=$(element).find('.wa-tiyu-rank-basketball-row >a > div.wa-tiyu-rank-basketball-rate').text().trim();
arrUrl.push({rank:rank,name:name,win:win,lose:lose,rate:rate});
});
let DT=moment(new Date).format("YYYY-MM-DD HH:mm:ss");
console.log("在"+DT+"第"+`${num}`+"次爬取结果:");
num+=1;
console.log(arrUrl);
}
});
其实css selector的方式有很多,可以从外层一层层查找,也可就近直接查询;但严谨期间嵌套多层较为妥当 爬完后的数据可以直接再次渲染展示,也可以存入数据库存储